Have you ever seen code which at first look seems good.. but then as you try to figure it out (maybe to fix a bug), it just feels… wrong?
For some reason the code just feels really difficult to follow – for no obvious reason!
In this post, I’m going to explain one such occurrence that I ran into in a production codebase. The code looked ok, yet it was hard to understand. Why?
Let’s find out. We’ll also look at some examples of how you can avoid and discover problems like this more easily.
The problematic code
At first, it was difficult to say why this particular code was hard to understand.
The example I’ll show you is based on real code, but I’ve altered it so it’s better for the purposes of this article.
function uploadFile(path) { var file = cleanPath(path); checkConflicts(file); } function checkConflicts(file) { fileExists(file, function(exists) { moveFile(file, exists); }); } function moveFile(file, exists) { if(!exists) { moveFileToTarget(appDir, file); } } function moveFileToTarget(dir, file) { fs.rename(dir, file....); } |
This looks fairly good, right? We’ve got a couple of functions. Each function is short and does a specific task. That’s exactly what you would want.
You can clearly see that these functions are processing a file upload. The file path is cleaned up, filename conflicts are checked and finally the file is moved into the target.
Despite that, there’s actually a couple of problems here. But – I don’t know about you – at least I initially had some trouble articulating what they were.
Let’s make the example resemble the real code better. I’ll add in some extra noise:
function uploadFile(path) { var file = cleanPath(path); //stuff //stuff //stuff //stuff checkConflicts(file); } function checkConflicts(file) { //stuff //stuff //stuff fileExists(file, function(exists) { moveFile(file, exists); //stuff //stuff //stuff }); } function moveFile(file, exists) { //stuff //stuff //stuff if(!exists) { moveFileToTarget(appDir, file); } //stuff //stuff } function moveFileToTarget(dir, file) { //stuff //stuff //stuff fs.rename(dir, file....); //stuff //stuff //stuff } |
The individual functions are still reasonably short, but do you notice how the steps in the file upload process are suddenly a lot harder to follow?
Now imagine this code in a file with other functions mixed in. Or maybe the functions are in different order, or in different files. UGH, how can you ever make sense of that?
I’m going to spare you from having to read an example with that – I’m sure you can imagine it would be pretty bad :)
Looking closer at the problem
Let’s look at the structure of our code. I’ll draw a handy picture here which illustrates the function call path:
function uploadFile(path) { var file = cleanPath(path); checkConflicts(file); } function checkConflicts(file) { fileExists(file, function(exists) { moveFile(file, exists); }); } function moveFile(file, exists) { if(!exists) { moveFileToTarget(appDir, file); } } function moveFileToTarget(dir, file) { fs.rename(dir, file....); } |
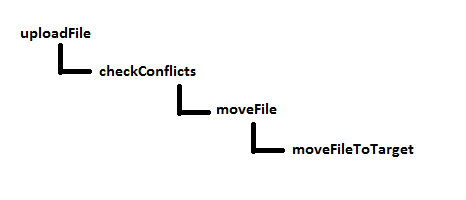
This is quite literally a sequence of steps – it resembles a staircase!
We can also say that with each step in this sequence, we are nesting one level deeper. This makes it harder to get the whole picture.
To understand this process, you need to find out all the steps in it. As long as we have a small amount of code it’s fine even if it nests like this, but as I added more noise (like you would have in real code), it became harder to follow.
Why is that?
When you look at a function, you have certain moving parts to keep in mind. What are its parameters? Does it use values from other scopes or closures? If it contains any control flow, such as loops or conditionals, what code path will it take with the parameters given?
Now you need to do this again and again, on each level. And because they’re all separate functions, the more you have the harder it’s to put together the whole picture because of all the moving parts.
This style of code is especially prevalent in asynchronous functions, as you often need callbacks.
Solving the problem
So what’s the solution to this problem?
We can make it more linear and lay out the process in a single function instead:
function uploadFile(path) { var file = cleanPath(path); var conflicts = checkConflicts(file); if(!conflicts) { moveFileToTarget(appDir, file); } } |
Wow, such a huge impact from such a small change!
But wait. This can’t work! All of our previous functions were asynchronous, and this code is obviously not async because there are no callbacks anywhere!
Yeah I cheated a bit, but I have a good reason…
There’s another problem here which prevents us from fixing it.
Even though our functions do small, specific tasks, it’s impossible to reuse them here!
Who would’ve known?
function checkConflicts(file) { fileExists(file, function(exists) { moveFile(file, exists); }); } function moveFile(file, exists) { if(!exists) { moveFileToTarget(appDir, file); } } function moveFileToTarget(dir, file) { fs.rename(dir, file....); } |
You can probably spot a flaw here: None of the functions have callback parameters, so we can’t get a result back.
But even then, the only really reusable function here is moveFileToTarget. If you look at the other two, they both are infact hardcoded for only one specific use case!
- If you call
checkConflicts… it always moves a file - If you call
moveFile… it always moves things into a specific directory
Okay, let’s fix it for reals this time. No cheating!
function uploadFile(path) { var file = cleanPath(path); checkConflicts(file, function(conflicts) { if(!conflicts) { moveFileToTarget(appDir, file); } }); } function checkConflicts(file, callback) { fileExists(file, callback); } function moveFileToTarget(dir, file) { fs.rename(dir, file....); } |
This time, I fixed the checkConflicts function so we can easily reuse it. I also removed moveFile, since it became completely unused. But if it had some extra code which is still necessary, we could easily have moved it into the callback on line 4 forwards.
The code for uploadFile is only a tiny bit more complex than my “cheaty” version.
What’s the result?
The code is a lot easier to follow now. We can instantly see the entire process for the file upload, just by looking at uploadFile. We eliminated the staircase path entirely, and the sequence is now very linear.
As an added benefit, we made the checkConflicts function reusable. If we ever need the same functionality elsewhere, it’s no longer tied down to this specific process.
How to prevent this from happening in the first place?
The original programmer clearly had good intentions. Let’s split up the code into a couple of logical chunks – small functions which do a specific task – like we’ve been told to do time and time again.
Is it a bad idea to split code into functions? No.
But splitting code too early can be.
When you’re working on a piece of code, usually your main thought is to get that specific process in place and get it working. When you’re in that mindset, it’s very easy to introduce functions which have this problem: Accidentally creating a function which is so coupled to your process, that it doesn’t really serve any purpose whatsoever.
Here’s a couple of general guidelines I like to follow to try and avoid these kinds of problems:
- Only split code into functions if not doing so would lead to duplication
- Try to visualize the sequence of actions fully, in your head, on paper, using tools – whatever works for you
- Splitting the sequence into chunks or specific steps which can be done in isolation can also help
This might be a bit controversial – but I think long functions can be okay! You need to use some judgement with this, but just because a function is longer than the usually suggested 5-10 lines doesn’t automatically mean you need to split it. The best indication of when you do need a new function is if you would otherwise need to duplicate code you already wrote.
If you can visualize the process in some way, it gives better insight into the last point – the individual steps. Nearly everything in programming is composed of steps. If you can see the bigger picture, you can then break it down more easily into functions if necessary – and reusable functions at that.
There is also another way of avoiding this. When we tried to first fix the code, it quickly became apparent that none of the other functions were reusable. The problem is you usually don’t know about this until much much later. Normally you only see this when you try to refactor your code, fix bugs or otherwise change it.
However, if you write unit tests for your code – especially if using test-driven development – you can spot this before it even happens!
Let me give you an example with the checkConflicts function.
One of the basic ideas behind unit testing is being able to test your code isolated from the rest of it. If we look at the original version of checkConflicts, there’s just no way we can test it isolated:
function checkConflicts(file) { fileExists(file, function(exists) { moveFile(file, exists); }); } |
The reason for this is of course that in order to run this function, it also needs to move a file.
If we had written a simple test for this function – perhaps something like this…
it('should should tell me if a file exists', function() { var file = 'some-file.jpg'; checkConflicts(file, function(exists) { assert.true(exists); }); }); |
If we were to run this test – in fact, even if we just took that code and ran it without the test – we would immediately find out these types of issues with the checkConflicts function. It would be very difficult to make this test pass when our function does other things besides what it should.
As a bonus, this can also help with the visualization of the problem. Our tests can help us define the responsibilities for each function in terms of simple human readable instructions, like “it should tell me if a file exists”.
Interested in learning more about unit tests? Want to read more practical JS tips like this one? Sign up for my mailing list with the form below.